Сравнение DataBook, DataPortal, DataHub, Amundsen, Metacat и прочих инструментов data discovery
Проблема
В data-driven компаниях, уделяющих много внимания метрикам, аналитике и т.д., появляется большое количество источников данных, таких как базы данных, а также таблицы и колонки в них.
Обычно есть несколько продуктовых команд, в каждой из которых есть своя аналитическая подкоманда и опционально дата-инженеры (да, скилл дата-инжиниринга в каждой продуктовой команде является обязательным условием для подхода data-mesh). Каждая из таких подкоманд отвечает за свой домен, соответственно только она понимает как и какие данные собираются в хранилище, что они означают, какова актуальность существующих таблиц и какие проблемы присутствуют в данных.
Can I trust this data?
Это создает сложность для аналитиков из других команд в навигации по источникам данных, выходящих за пределы их домена. Данную проблему хорошо описал AirBnb в своем блоге. Аналогичная ситуация возникает для нового аналитика, недавно присоединившегося к команде. Когда он получает свой первый таск, первым делом ему нужно понять где лежат соответствующие данные, и часто это самая долгая часть выполнения задачи.
Если вспоминать пирамиду потребностей в data science, о которой уже не раз писали на medium (и даже на forbes, но все же первыми были LinkedIn), то data discovery находится где-то между prep (cleaning & anomaly detection) и analytics (metrics, segments).
Это означает, что при плохо налаженном процессе data discovery все downstream процессы, такие как аналитика, анализ A/B/N-тестов и machine learning будут страдать как минимум в скорости, а чаще еще и в качестве.
Решения
Аналогично понятию DWH, когда все структурированные данные компании собраны в одном месте (не путать с полу- и неструктурированными, для которых есть понятия Data Lake и Data Swamp), нужен некий тул, собирающий в одном месте все структурированные данные о данных.
Для данных о данных придуман собственный термин — метаданные.
Теоретически всем метаданные можно model-agnostic путем разделить на Application Context (семантика и описание), Behavior (как данные получены и как используются) и Change (для Change Data Capture). Подробнее можно прочитать в этой статье или в указанном ниже блог-посте от Lyft.
Практически, может понадобиться:
- список всех баз данных, таблиц/вьюх и их полей
- что означают данные + теги
- создатели/owner’ы таблиц
- lineage (как собираются), возможно в виде ссылки на файл ETL в git или dag в airflow.
- дата начала сбора данных и дата/время последнего обновления
- периодичность обновления
- тип таблицы: справочник аттрибутов, факты, историческая таблица
- имеющиеся проблемы в источнике
- кто и когда последний раз использовал данный источник
- статистика по данным (кол-во строк, уникальных строк, min/max) + семплы
- SLAs, dependencies, schema evolution, physical location and replication, suitable clients, alerting rules, sql examples, etc.
Главными must-have фичами в таком туле можно считать наличие функционала добавления description’а к схеме/таблице/колонке, а также наличие поиска по ключевому слову среди всех возможных таблиц и их полей. Однако, в отличии от поиска в том же Dbeaver, поиск должен происходить одновременно во всех дата-сорсах в компании, таких как OLTP (допустим postgres) и OLAP (допустим clickhouse) базы данных, hadoop/hive и т.д., а также учитывать при ранжировании “популярность таблицы” в поиске или в кол-ве запросов в данный источник.
Также, данный тул может помочь в таких процессах, как Tech stewardship (как по мне, это прослойка между Data ownership и Business stewardship) — см. презу по Data Strategy c последнего DataFest)
Профит от данного тула — значительное ускорение поиска нужного источника и понимание его актуальности, а также достоверность построенных выводов по данных (поскольку ты заранее знаешь, где в твоих данных bullshit).
1. Wiki
Обычно в компании используется какая-либо wiki-система (например Confluence/Notion/Coda), в которой можно создать пространство под конкретно эту задачу и вручную указать желаемую информацию. Я лично встречал на практике 4 компании, которые используют таблицы в Confluence. В целом это хорошая идея для старта, и многие компании используют данный вариант (в том числе несколько наших отечественных IT-гигантов).
Из очевидных недостатков такого подхода можно выделить необходимость для каждой новой таблицы создавать свою страницу и перечислять поля, хотя это можно доставать автоматически из самой БД и создавать заглушки.
2. Dashboard & BI tools
Кажется логичным внедрением данного функционала в инструменты для исследования данных и построения дашбордов (BI-tools). Два самых известных open-source решение — metabase и superset.

В Metabase (у которого кстати помимо облачной on-premise версии есть отличное desktop-приложение, а значит его можно попробовать без всякого рода деплоя) есть поиск таблицы по всем подключенным источникам. Однако, поиск по колонкам отсутствует, а также нет возможности добавлять кастомное описание (одна из двух основным хотелок). Кроме того, в Metabase нет коннектора в clickhouse, который сейчас набирает популярность.
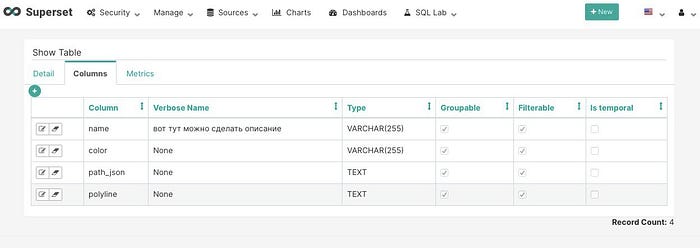
В Superset есть поля для добавления кастомного описания и встроенная работа с owner’ами таблиц, также туда можно легко (без знания sql) накинуть в дашборд с статистикой по таблице (кол-во строк, мин/макс и т.д.). Однако, полный список всех таблиц и их полей есть только в SQL Lab view (что не очень удобно). Для просмотра таблиц и добавления описания необходимо отдельно объявлять каждую таблицу.
3. Custom tool
Для крупных data-driven компаний данная проблема стоит особо остро. Обладая достаточными ресурсами, неудивительно, что многие их них разработали собственные инструменты, совмещающие в себе как введенную вручную информацию, так и метаданные, получаемые автоматически из конкретного источника.
Примеры:
- Amundsen в Lyft — https://eng.lyft.com/amundsen-lyfts-data-discovery-metadata-engine-62d27254fbb9
- Metacat в Netflix — https://netflixtechblog.com/metacat-making-big-data-discoverable-and-meaningful-at-netflix-56fb36a53520
- Marquez в WeWork — https://www.datacouncil.ai/talks/marquez-a-metadata-service-for-data-abstraction-data-lineage-and-event-based-triggers
- DataHub в LinkedIn — https://engineering.linkedin.com/blog/2019/data-hub
- Databook в Uber — https://eng.uber.com/databook/
- DataPortal в AirBnb — https://medium.com/airbnb-engineering/democratizing-data-at-airbnb-852d76c51770
- DAL в Twitter — https://blog.twitter.com/2016/discovery-and-consumption-of-analytics-data-at-twitter
- Data Catalog для Google Cloud — https://cloud.google.com/data-catalog
- Lexikon в Spotify — https://labs.spotify.com/2020/02/27/how-we-improved-data-discovery-for-data-scientists-at-spotify/
- Artifact в Shopify— https://medium.com/data-shopify/how-were-solving-data-discovery-challenges-at-shopify-f0bbfcbd8d30
- Data Catalog в Lime — https://medium.com/lime-eng/why-and-how-we-built-a-data-catalog-at-lime-6cb79419b7e2
Первые 4 разработки (выделены курсивом) выложены в open-source, позволяя другим компаниям адаптировать их у себя. Некоторые из этих инструментов уже упоминались на medium (раз, два, три), и даже была попытка их сравнения. Однако я не совсем согласен с пунктами в этом сравнении (видимо учитывалась версия, используемая в самой компании, а не open-source), также не было описания архитектуры и примера подробного разбора какого-либо их них, тем более в русско-язычном поле.
В данной статье ниже я более подробно сравниваю наиболее известные инструменты (в том числе с открытым исходным кодом) с точки зрения наличия необходимых фич, а также простоты развертывания и эксплуатации (в многом это определяется используемым стеком).
Архитектура таких решений
Коротко данные решения состоят из 3 основных блоков:
- Ingestion layer (он же databuilder в Amundsen, он же Metadate API в Marquez, он же Connector Manager в Metacat).
Суть данного блока в получении метаданных от различных источников в DWH. Он может работать по двум моделям — push (когда сам источник сообщает о появлении новой таблицы или изменении схемы через сообщение в kafka) и pull (когда в определенные интервалы планировщик сам делает запросы для получения метаданных из источника). В варианте с pull моделью данный блок представляет из себя коннекторы в RDBMS, где с помощью sql-запросов можно получить список всех таблиц и колонок, а также коннектор, работающий с Hive-metastore, в котором можно покрыть большинство данных (написав DDL), хранящихся в каком-либо виде в системе HADOOP.
- MetaData strorage&indexing
Данный блок необходим для хранения метаданных по выбранной модели, а также предоставляет функционал текстового поиска. Второй вариант в большинстве случаев работает на ElasticSearch, а первый — на графе Neo4j или Apache Atlas. Собственно информация, которая может отображается в туле (таблицы, пользователи, дашборды, job’ы), ограничена моделью, т.е. какие сущности и связи между ними сохраняются в базе метаданных. Очевидно, что одна из самых ожидаемых фич для этого блока — умение хранить связи между таблицами и строить lineage, а также внедрение ml-моделей в этот список.
- RestAPI & UI
Наверное самый простой пункт — отображение результатов поиска и информации из графа.
2. Сравним!
В основном сервисы сравниваются с точки зрения того, какие коннекторы имеет Ingestion layer (подобный разбор уже был здесь) и с какими сущностями умеет работать metadata layer.
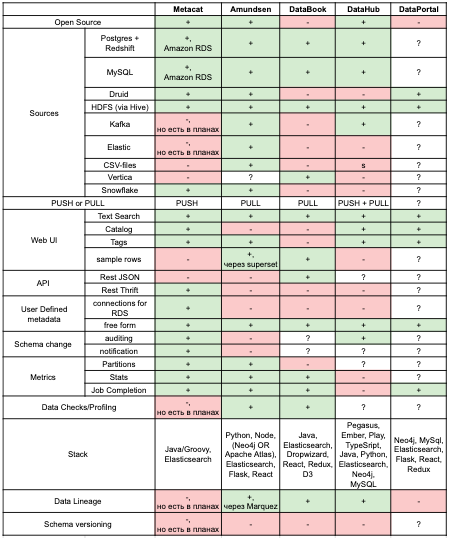
Сравнение сервисов можно увидеть в таблице выше. Данные актуальны на момент написания статьи (май 2020). Для закрытых проектов часть фич угадывалась по скриншотам из статей, а часть остается загадкой и поэтому в таблице можно встретить знаки вопроса.
Metacat pros: Имеет самое большое кол-во коннекторов, и большинство фич в нем либо уже присутсвует, либо есть планы по их добавлению. Также вкусным выглядит “Hive metastore optimizations”, поскольку стандартный вариант не справляется с нагрузкой записи нескольких тысяч новых партиций (хотя большинству компании скорее всего хватит стандартного). Последней плюшкой является отправка события об изменении схемы в Amazon SNS. Это должно помочь с версионированием схемы.
Metacat cons: В данный момент lineage все еще не реализован. Очевидным фактом является то, что применяя большое кол-во внутренних фреймворков, дубль своего решения в open-source не может быть стабильным (об этом хорошо написали LinkedIn в статье про open-sourcing DataHub). С этим сталкиваешься сразу же — у меня так и не получилось нормально задеплоить через docker-compose, пришлось локально через tomcat (и это в эру победившего cloud’а!). А учитывая используемый стек в виде java и groovy (та же java) вряд ли получится доработать/расширить функционал силами дата-аналитиков.
Уберовский DataBook, кмк, на сегодняшний день можно отправлять на свалку. Он конечно красивый, адаптированный под их инфру, но сильно ограничен как по источникам данных, так и по функционалу. Странным выглядит подсчет статистики по запросам к таблице — вместо использования метаданных от источника, подсчет ведется на основе исходников запросов и их же open-source sql-парсера. В момент старта разработки уже был DataHub, но тот не умел во много дата-центров. Теперь же есть Metacat, который вроде бы решает эту проблему.
DataHub pros: это такой монстр, который умеет и PULL, и в PUSH модель (естественно через kafka, которую в этой компании и разработали), что позволяет получать изменения в схеме в real-time. Для получения метаданных из RDBMS проект использует пакет pydbms, что позволяет единым образом тянуть инфу из IBM DB2, Firebird, MSSQL Server, MySQL, Oracle, PostgreSQL, SQLite and ODBC connections, и автоматически начать поддерживать другие БД при появлении их в пакетеs. Кстати, это единственный из представленных инструментов, который умеет отображать топики кафки в качестве источников (Amundsen умеет только показывать список партиций по уже готовому списку топиков). Что выглядит довольно странным, учитывая что BI-tools for BigData давно научились работать с топиками как с каталогом таблиц, и даже считать аналитику с построением дашбордов.
DataHub cons: почему-то в публичной версии из модели данных вырвали дашборды и т.д., оставив только таблицы и пользователей. Не встретив надписи Vertica в списке источников я был расстроен и удивлен. Сам инструмент устроен довольно сложно (коротко архитектуру уже рисовали на medium), и вот мешок того что ставится при деплое сервиса (docker-compose.yml лучше не открывать), причем как вы понимаете процесс этот очень долгий. Опять же стоит упомянуть проблему получения стабильного открытого решения дублируя внутренние разработки. Про используемый стек пожалуй промолчу. Напоследок, стандартно для LinkedIn, интерфейс перегружен и вызывает эстетическую неприязнь.
Большей части компаний real-time push изменений/добавления схемы не нужен, если на это не завязаны какие-то job’ы или другие внутренние процессы.
DataPortal: как всегда AirBnb выдал визуально красивое решение с приятным стеком и сопроводив ванильной статьей. В модели есть дашборды, посты в Knowledge Repo, а также employee- и team-центричность (с добавлением в избранное, статисткой использования и т.д.). Единственный момент — забыли выложить в свой open-source. Перечисленные выше плюшки скорее всего и есть причина закрытости проекта, т.е. невозможность избавить проект об большого кол-ва других внутренних систем.
Marquez я не стал выделять отдельно ввиду его ограниченности. Он имеет ingest API, но для каждого источника коннектор нужно написать отдельно. Кроме того, поиск в UI довольно ограничен, а description’ы можно добавить только через API (но это не точно). Однако не спешите шеймить, его основная ценность не как end-to-end решение, а в том что он может строить потрясающие графы в интеграции с другими системами. Мы еще вернемся к нему позже в этой статье.
Amundsen ворвался в мое сердце своим списком источников, среди которых есть такие изюминки как snowflake, Neo4j, BigQuery и RestApi (в который можно упаковать почти все). Также есть экстактор mode дашбордов (жалко что не superset), что позволяет начать использовать дашборды в модели метаданных. К сожалению, нормальная column-stats отсутсвует в открытой версии. Аналогично и с lineage, но это поправимо (об этом позже). Подробнее разбор сервиса читаем ниже.
К моему огорчению, никакой из инструментов из коробки не работает из clickhouse’ом, западные компании не спешат адаптировать у себя эту маленькую (простую и обрезанную), но гордую БД. К счастью, в Amundsen есть общий класс для всех БД, работающих c SQLAlchemy, и значит туда через кастомный запрос добавить клик.
4. Test drive
Этот блок в статье богат техническими подробностями и будет полезен тем, кто хочет посмотреть пример использования и попробовать поднять такой инструмент у себя.
Конечно, мне захотелось разобрать подробнее какой-либо инструмент и уже начать использовать его в повседневной работе. Мой выбор пал на Amundsen, в пользу этого решения есть довольно много фактов:
Во-первых, его достаточно легко задеплоить хоть в облаке, хоть локально. Одно из требований для меня — это возможность обычному дата-аналитику начать пользоваться инструментом без опыта в data-engineering’е. Часто в компаниях аналитики могут запилить MVP нового продукта/сервиса, оценить как она работает и только затем передавать его на разработку/эксплуатацию специализированной команде.
Во-вторых, основной его стек — это python и airflow, а также модульная структура, что позволит в случае необходимости допилить данный инструмент под себя (да, я считаю что аналитики должны уметь кодить). Не нужно возиться с java’ой, на которой написано большинство подобных систем.
В-третьих, самый большой список data-source’ов, с которыми работает сервис.
В-четвертых, я неравнодушно дышу к тому что делает Lyft.
Итак, погнали. Клонируем себе репозиторий. Не удивляйтесь, что в репо названия папок выглядят странно, это просто вложенные репозитории (submodules), в локальной папке названия адекватные.
Далее, переходим в папку с репо и стартуем приложение. Для запуска второй команды должен стоять docker (на mac он ставится как обычное приложение с помощью мышки). Полный запуск на macbook air 2017 составляет в районе минуты.
Открываем и начинаем смотреть интерфейс на http://localhost:5000, но без тестовых данных это как-то так себе.
В репо включены тестовые метаданные для Hive, давайте поставим и посмотрим. Любой data-analyst в целом понимает что означают данные команды.
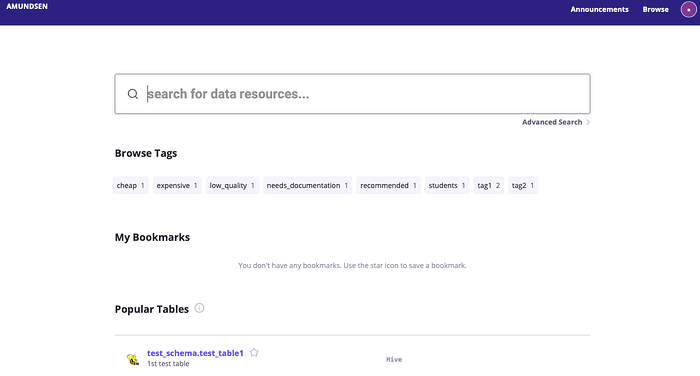
Теперь точно все готово. Открываем ссылку выше и видим главную страницу с полем для ввода. Что сразу бросается в глаза — так это отсутсвие древовидной структуры, что мне кажется сильным недостатком. Если быть честным, я попробовал несколько сервисов, и только в только в DataHub от LinkedIn была структура в виде хлебных крошек.
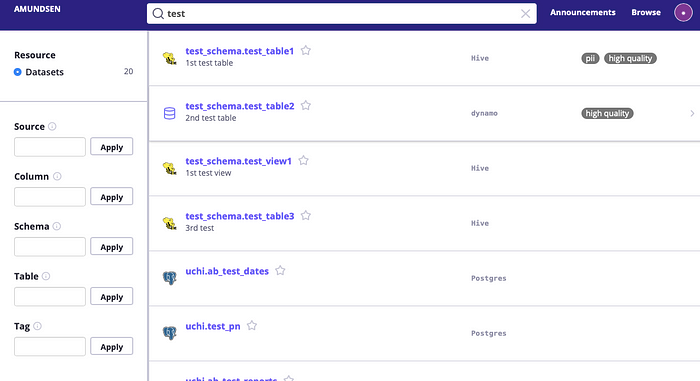
Вводим запрос + Enter — и мы попадаем в окно результатов поиска. На эту форму можно также перейти, кликнув на “Browse” в правом верхнем углу. Важный момент — искать по названию поля можно только на этой экране, что было для меня неожиданностью. Белые буквы на сером фоне — вручную расставляемые теги, одна из супер-полезных фичей.
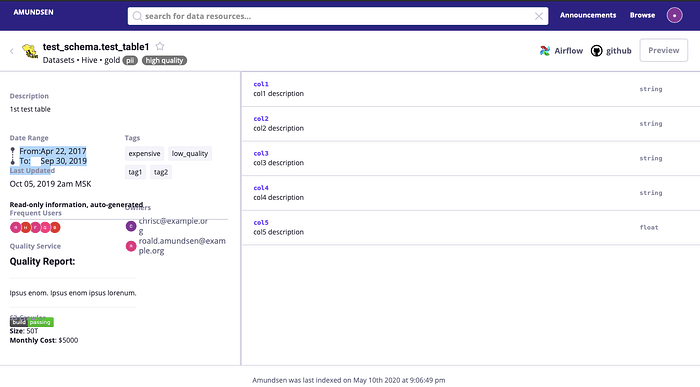
Если перейти на форму конкретной таблицы, можно увидеть список столбцов и кнопки для добавления description. К сожалению остальные поля не добавляются автоматически в при подключении того же postgres’а. Однако, посколько они есть в модели графа, их можно добавить в файле экстракта инфы из постгреса.
Давайте постестим Postgresql
Все просто: берем файл, добавляем его к своим dag’ам (единственное, в 47й строчке мне пришлось изменит адрес Neo4j на localhost, без этого не работало), либо для разовой загрузки удаляем из него куски кода, относящиеся к airfow и запускаем как обычный python-скрипт, пример есть там же.
Кстати, саму модель в графе и что сейчас в ней лежит можно посмотреть в интерфейсе самого Neo4j (http://localhost:7474/browser/), если конечно есть скилл в Cypher (SQL for graphs). Например вот так можно вывести список таблиц — MATCH (n:Table) RETURN n LIMIT 25.
Общее впечатление: того, что есть в open-source версии явно не хватает. Хочется для того-же Postgres’а получать статистику использования, граф зависимостей и т.д. Превью таблицы доступно только после установки superset.
Для получения lineage’а можно использовать Marquez, у которого есть хорошая интеграция с amundsen, при этом он умеет парсить sql в dag’ах airflow. Marquez — это такой космолет, написанный на Java/Postgres (core)/Cayley (graph)/Elastic(search), который предоставляет Rest API для объявления датасорсов/job’ов (push way), хранит это у себя в формате Apache Iceberg (разработка netflix) и предоставляет интерфейс. Весь космос в том, что marquez имеет интеграцию с airflow, парсит и версионирует SQL-джобы, на основе них строит граф из заранее объявленных датасорсов и привязывает версию датасета к запуску определенной версии джобы. Таким образом, найдя ошибку в коде, можно быстро понять в каких таблицах и за какой период появились невалидные данные. Более того, он умеет работать сразу с несколькими инстансами airflow и позволяет трегирить запуск DAG’а на одном после выполнения DAG’а. на другом. Фактически он решает задачи data discovery, data lineage и data governance. Заявлено, что он model-agnostic (как поручено в статье от Ground), хотя я не понимаю как это возможно при условии RestAPI (highly opinionated) и жесткой dbtables. Подробнее смотри видео тут или презы тут.
Планы
Доработать все недостатки в Amundsen, добавить clickhouse и выложить в open-source. Также, я точно поиграюсь с Marquez и его интеграцией с Amundsen, возможно напишу еще одну статью или выложу что-нибудь на github.
Update:
- Amundsen перешел в инкубатор Linux foundation AI (LFAI), теперь у сервиса отдельный блог на medium с ежемесячными апдейтами.
- У Netflix вышел отдельный инструмент для in-memory БД — Dynomite и Cassandra.
- DataDoc — инструмент от Criteo.
P.S.: Если тебе понравилась стать, в качестве благодарности можешь купить мне кофе на https://www.donationalerts.com/r/stats_data_ninja или https://buymeacoffee.com/koch.
